⚠ 私自身まだ SAA 合格していないので一応 SAA 合格しましたが、記載している情報の信頼性は全く保証できません。
SAA 対策のための自分用メモです。
主に教材として使用しているのは以下の2点です。
モチベーション
SAA-03 の公式模擬試験があったのでトライしてみたら、DR戦略でチンプンカンプンだったので、公式解説をみながら理解を深めてみる
DR戦略とは
- DR = Disaster Recovery ⇛ 災害復旧
- 試験内では普通に略称が使われるとのこと
用語
RPO:Recovery Point Objective
- 内容をどこまで復旧させるかの目標
- 要はデータロスをどこまで許容するかということ
- 実際は「時間」の単位で語られるっぽい
- どれだけの時間のデータロスを許容できるかみたいな
- バックアップの頻度に依存
RTO:Recovery Time Objective
- 復旧時間の目標
- どれくらいのダウンタイムを許容するか
- 復旧までの時間に依存
戦略の種類
4パターンが存在し、それぞれパフォーマンスとコストでトレードオフとのこと。
- バックアップとリストア
- バイロットライト
- ウォームスタンバイ
- ホットサイト/マルチサイト・アプローチ
以下のように、基本的には右側のほうがRTOとRPOを小さくできるが、コストがかかるという感じ。
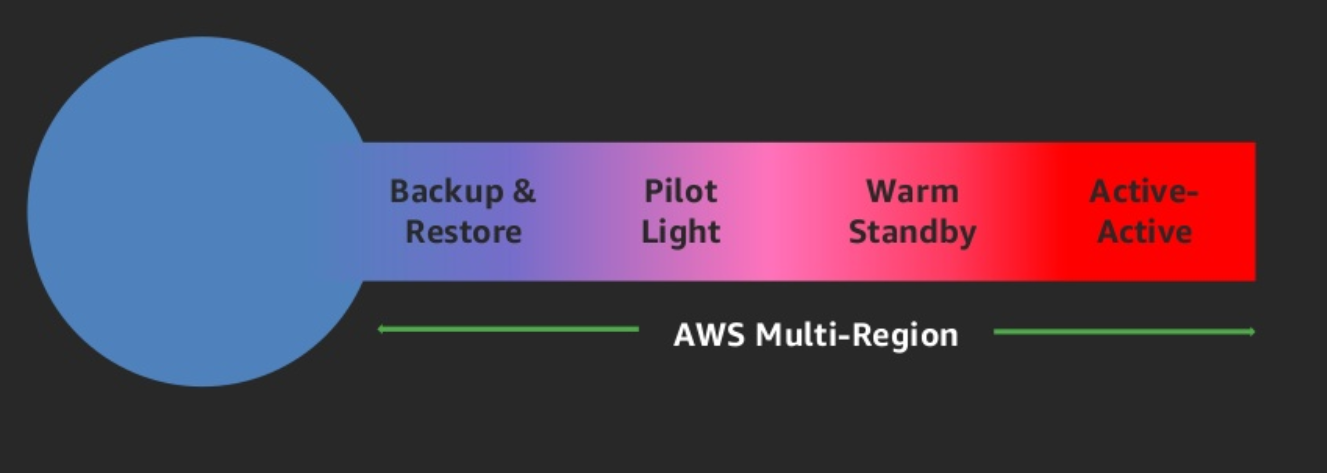
※画像は以下の公式からお借りしてます。
ディザスタリカバリ (DR) を計画する - 信頼性の柱
バックアップと冗長ワークロードコンポーネントを配置することは、DR 戦略の出発点です。 RTO と RPO は、ワークロードを回復するための目標です。これは、ビジネスニーズに基づいて設定します。ワークロードのリソースとデータのロケーションと機能を考慮して、目標を達成するための戦略を実装します。ワークロードのディザスタリ...
docs.aws.amazon.com
なお、基本的にはこちらの公式リンクに詳細が記載されています。
バックアップとリストア
特徴
- 通常時はバックアップのみなのでコストが低い
- RTOは24時間以内
通常時
- 基本的に、アプリケーションの実行はオンプレ側で行う
- データはオンプレか、クラウド上のものを使う
- データがオンプレの場合は、クラウドに定期的にバックアップを取る
- データがクラウドの場合は、定期的にスナップショットを取る
障害発生時
- ホスティング環境は、クラウド上に構築する
- ニュアンス的には障害発生時に構築する
- データは、クラウドにあるバックアップを使用してリストアする
パイロットライト
特徴
- バックアップとリストアに似ている
- よくある説明では、「コア部分のみ常にクラウド上で動かす」という記載があるが、AWSの公式模擬試験では「あらかじめEC2インスタンスを構築し、停止状態にしておく」というのがあった
- つまり、EC2インスタンスの停止状態も、一応コアが既に動いている扱いということか?
- RTOはだいたい数時間
通常時
- アプリケーションはオンプレ環境で動作させる
- データベースはオンプレかクラウド上で動作させる
- オンプレで動作させる場合は、クラウド上にレプリケーション等で同期をとる
- つまりデータベースは稼働しておくということ
- クラウド上で動作させている場合は、まさにコア部分がクラウド上で動いていることになる?
- オンプレで動作させる場合は、クラウド上にレプリケーション等で同期をとる
障害発生時
- ホスティング環境は、停止していたEC2インスタンスを起動させる
- Route53等で、稼働先をクラウド上に切り替える
- データベースはクラウドにあるものをそのまま使う
- オンプレのDBを使用していた場合は、クラウド上のレプリカにフェイルオーバーする
ウォームスタンバイ
特徴
- RTOはだいたい数分
- コストは高くなる
通常時
- アプリケーションはオンプレでも稼働するが、最小構成でクラウド上でも稼働させておく
- Route53を常に起動しておき、オンプレにルーティングするようにしておく
- データベースはパイロットライトと同様
- つまりクラウド上で常にレプリカが同期状態
障害発生時
- ホスティング環境はRoute53等でルーティングをEC2インスタンスに変更
- AutoScalingの機能で障害発生時のタイミングで自動すケースさせる
- データベースはパイロットライトと同様
- つまりクラウド上のレプリカにフェイルオーバー
ホットサイト/マルチサイト・アプローチ
特徴
- RTOは数秒が可能
- 非常に高コスト
通常時
- アプリケーションもデータベースも常にクラウド上で稼働させる
- マルチリージョンで稼働させておくことがポイント
- Route53でフェイルオーバーを有効にしておく
障害発生時
- Route53のフェイルオーバーが働く
所感(ポエム)
- バックアップとリストアとパイロットライトは、あらかじめEC2インスタンスを用意しておく(停止状態でスタンバイしておく)かどうかの違いか?ならばパイロットライトのほうが完全優位な気がするが・・・
- そもそもEC2停止でスタンバイなら、EBSボリュームのコストしか差が出ないはず・・・
- ウォームスタンバイは、それなら最初から全部クラウドで運用すればいいじゃないかという感じ
- 最小構成にしろ、クラウド上で運用しているならオンプレとクラウドのダブルメンテになるから保守大変じゃない?と思うが・・・
- 結果的に、個人的には素人考えだけどDR戦略をしたいなら以下でいいんじゃないと思ったり・・・
- CloudFormation等で構成をテンプレート化していつでも再現できるようにしておく
- 基本はクラウドで運用する
- Route53でいつでもリーティング変更できるようにしておく
- マルチリージョンでデータのバックアップ(またはレプリケーション)をとる
- 災害発生時(リージョンそのものがダメになったとき←そもそもそんなことあるのか問題もあるけど)、異なるリージョンでCloudFormationから環境を再構築
- データベースもフェイルオーバーする
- Route53 でルーティングを新しく環境構築したリージョンに変更する
コメント