現在担当している案件で、EC2インスタンス障害復旧に関する設定しています。
調べてみますと、EC2インスタンスの障害復旧方法としては大まかに以下の2手法があることがわかりました。
- デフォルトの自動復旧を利用する方法
- 2022年4月頃、EC2インスタンスには「Simplified automatic recovery」という機能が追加され、デフォルトでEC2インスタンス障害発生時に自動復旧する仕様となったとのこと
- 参考: https://aws.amazon.com/jp/about-aws/whats-new/2022/03/amazon-ec2-default-automatic-recovery/?_fsi=mVMeDfqv
- ClowdWatchAlarmでメトリクスを監視する設定をして、復旧設定する方法
- こちら従来からの障害復旧手法
これらについて、どちらを使用するべきなのか、または両方使用するべきなのかを調査した内容を備忘録します。
結論
先に結論ですが、動作確認してみた結果、上記の2手法は異なると思われます。
(「Simplified automatic recovery ≠ CloudWatchAlarmメトリクス監視による復旧(再起動)」)
結果的には、両方とも設定する必要があるかなという認識となりました。
両者の比較
Simplified automatic recovery について
前述の通り、現在はEC2インスタンスを起動した際にデフォルトで有効になっている自動復旧設定です。
- 公式(日本語版)
- 公式(英語版)
実際の発動条件等は非公開のようです。
CloudWatchAlarmメトリクス監視による復旧(再起動)について
EC2インスタンスでは、インスタンスの障害を検知するチェックとして以下の2つのメトリクスが存在するようです。
- StatusCheckFailed_Instance(インスタンスステータスチェック)
- StatusCheckFailed_System(システムステータスチェック)
ざっくり感覚論で区別すると、「インスタンスのステータスチェック」はソフトウェア的な障害がメイン、「システムのステータスチェック」はハードウェア的な障害がメイン、という認識です。(詳細は公式か下記参考サイトを確認ください)
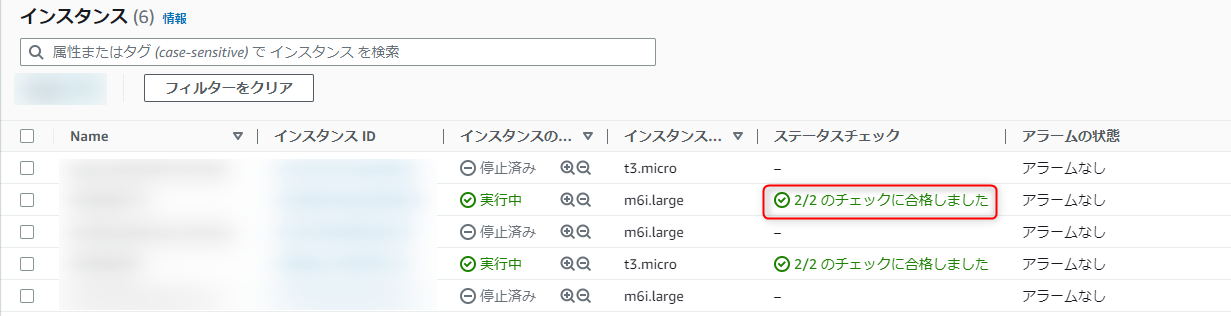
この2つのステータスチェックは、以下のようにEC2インスタンスのコンソール画面でもよく出てくるやつです。
ここでいう「2/2」というのが、インスタンスステータスチェックとシステムステータスチェックのことのようです。
参考
- https://dev.classmethod.jp/articles/cloudwatch-metrix-memo-1/
- https://dev.classmethod.jp/articles/ec2-auto-recovery-test/
「Simplified automatic recovery」と「CloudWatchAlarmメトリクス監視による復旧(再起動)」の関係について
シンプルな疑問として、「Simplified automatic recovery」は上記の「インスタンスステータスチェック」と「システムステータスチェック」のそれぞれをカバーしているのか?「Simplified automatic recovery」があれば、ClowdWatchAlarmの設定は不要になるのか?という疑問があります。
調べてみると、「Simplified automatic recovery」が「インスタンスステータスチェック」と「システムステータスチェック」の両方をカバーしているのか?については、カバーしていると記載されているブログ記事等がいくつかみつかりましたが、公式では「システムステータスチェックが失敗した場合~」と書かれていて直感的にはカバーしていないように思われます。(公式は、一見「Simplified automatic recovery」に言及していないように見えるが、英語版でみるとしっかり「Simplified automatic recovery」という主語を使っている)
また、「Simplified automatic recovery」があれば、ClowdWatchAlarmの設定は不要になるのか?についても、大手AWS代理店のサイト等では、「両方設定しても大丈夫だが、ClowdWatchAlarmの設定は削除しても大丈夫」と断言しているところもあります。
ということで、実際はどうなのか確認してみます。
動作確認
動作確認方法
動作確認をするうえで、「インスタンスのステータスチェック」と「システムのステータスチェック」をそれぞれ意図的に異常にするようにしたいのですが、「システムのステータスチェック」については意図的に実行できないようです。(どうやら有名な話のようですが)
(参考: https://dev.classmethod.jp/articles/ec2-auto-recovery-test/ など、いろいろなサイトで取り扱われています)
そこで、ここではテスト可能な「インスタンスのステータスチェック」についての動作確認を行います。「インスタンスのステータスチェック」についてだけでも「Simplified automatic recovery」と「ClowdWatchAlarmの監視設定」で挙動が違うなら、少なくともそれらは「異なる設定」と言えますので。
なお、インスタンスのステータスチェックについての動作確認は、以下サイトを参考にさせてもらいました。
(EC2インスタンス上で、 sudo ifdown eth0 を実行して強制的にNICを無効状態にしてステータス異常を起こす)
補足1
確かにハードウェアの異常を意図的に起こすことができないのはわかりますが、確認するすべがないのはいかがなことか・・・
AWS FIS(Fault Injection Simulator)という意図的に障害を起こしてテストできるサービスがあるようですが、こちらを使用してもシステムのステータスチェックは異常にできないようです。
それってどうなの?って思いますが・・・
補足2
後述しますが、EC2インスタンスの文脈において、「復旧」と「再起動」は異なる概念のようです。
インスタンスのステータスチェックに失敗した場合のリカバリー方法は「再起動」で、システムのステータスチェックに失敗した場合のリカバリー方法は「復旧」となります。
参考: https://dev.classmethod.jp/articles/cloudwatch-ec2-autorecovery/
動作確認条件
以下の条件で動作確認してみます。
- 「Simplified automatic recovery」のみ有効にして、ClowdWatchAlarmによる復旧/再起動設定はなしの状態で、「インスタンスのステータスチェック」異常を発生させる
- 「Simplified automatic recovery」を有効にしてかつ、ClowdWatchAlarmによる「StatusCheckFailed_Instance(インスタンスステータスチェック)」メトリクスの自動再起動を有効にして、「インスタンスのステータスチェック」異常を発生させる
上記それぞれの場合で、EC2インスタンスは再起動するのかを確認します。
動作確認結果
結果的に、以下のようになりました。
- →EC2インスタンスは再起動しない
- →EC2インスタンスは再起動する
つまり、どうやら、「Simplified automatic recovery」は「インスタンスのステータスチェック」による再起動に対応していないようです。
以上より、個人的な見解では、「Simplified automatic recovery ≠ CloudWatchAlarmメトリクス監視による復旧(再起動)」ということになります。
そのため、それぞれで設定する必要がありそうです。
少なくとも、「インスタンスのステータスチェック」は「Simplified automatic recovery」とは別で個別に設定する必要がありそうですね。
なお、「インスタンスのステータスチェック」による再起動と、「システムのステータスチェック」による復旧がバッティングしないようにするために、それぞれ監視時間を変えるべきという公式のアナウンスがありますので、注意してください。
(参考: https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/UsingAlarmActions.html )
↓アナウンスのスクショ

そもそも「復旧」と「再起動」は異なる
この概念が異なるということもあまり知られていない気がします・・・
ChatGPT4搭載のBingに、EC2インスタンスにおける復旧と再起動の違いを聞いてみました。
EC2インスタンスにおける、復旧と再起動の違いについてですね。
EC2インスタンスの再起動は、インスタンスを停止してから再度起動することで、OSやアプリケーションの再起動を行います。
一方、復旧は、インスタンスが障害を起こした場合に、自動的に別のホストに移動して復旧することを指します。
AWSでは、システムステータスチェックが失敗した場合に自動的に復旧することができます。
また、AWSでは2022年3月より、EC2インスタンスの自動復旧がデフォルトで実行されるようになりました。
また、「自動復旧」について、公式には以下の記載があります。
自動復旧では、インスタンスは別のハードウェアに移行されて再起動されます。
要約すると以下の感じでしょうか。
- 復旧
- 別ホストでOSを再起動
- 再起動
- 同一ホストでOSを再起動(もしかしたら同一ホストであることは保証されないかも)
なので、インスタンスのステータスチェックに失敗した場合はソフトウェア的な障害が該当するので再起動でよく、システムのステータスチェックに失敗した場合はハードウェア的な障害が該当するので復旧になるのかと思います。
参考
- https://dev.classmethod.jp/articles/cloudwatch-ec2-autorecovery/
- https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/UsingAlarmActions.html
まとめ
いろいろなサイトで、「Simplified automatic recovery」を設定しているならばClowdWatchAlarmによる自動再起動の設定は不要であるとか、ClowdWatchAlarmの監視で「StatusCheckFailed」メトリクスだけを監視すればいい、などという言及がありますが、自分で確認してみたところ、そのようではなさそうです。
AWSの代理店をやっている大手サイトでも、論調が異なっていたりするので、この「Simplified automatic recovery」による自動復旧は結構混乱させる概念なのかなと思います。(AWSが発動条件をしっかりアナウンスすればいいのにと思います)
あくまで個人で調査した内容を記載しておりますので、事実とは異なる可能性があることはご了承いただく必要がありますが、同じように悩んでいる方がおられましたらヒントになると幸いです。
コメント